今天,一个名为Supertonic的Swift库在GitHub上单日新增1128星,总星数突破5400。它宣称能在iPhone上以毫秒级速度运行多语言文本转语音,完全离线、无需GPU,甚至不依赖Core ML。在云端TTS成本高企、隐私监管趋严的当下,Supertonic试图证明:设备端语音合成可以既快又好。
这个项目在做什么
Supertonic是一个纯Swift编写的多语言TTS(文本转语音)引擎,通过ONNX Runtime在设备端原生执行。它解决的问题很明确:现有TTS方案要么依赖云端(延迟高、有隐私风险),要么在设备端性能不足或集成复杂。Supertonic将模型推理完全放在本地,支持英语、中文、日语、韩语等多种语言,且无需GPU加速。
为何此刻被关注
今天Supertonic的爆发并非偶然。过去一周,该项目已累计增长5879星,其中5月17日单日峰值达4565星。触发因素可能是开发者社区在Reddit和Hacker News上的讨论,以及一条演示其在M1 MacBook上实时合成语音的推文被广泛转发。此外,苹果在WWDC前后对设备端AI的强调,也让Swift生态中的此类项目获得了更多关注。
技术上有何不同
与常见的TTS方案相比,Supertonic有两个关键差异:
- 纯Swift + ONNX:不依赖Core ML或TensorFlow Lite,而是直接使用ONNX Runtime for Swift。这意味着模型转换路径更简单,且ONNX Runtime在CPU上的优化使其在无GPU设备上也能高效运行。
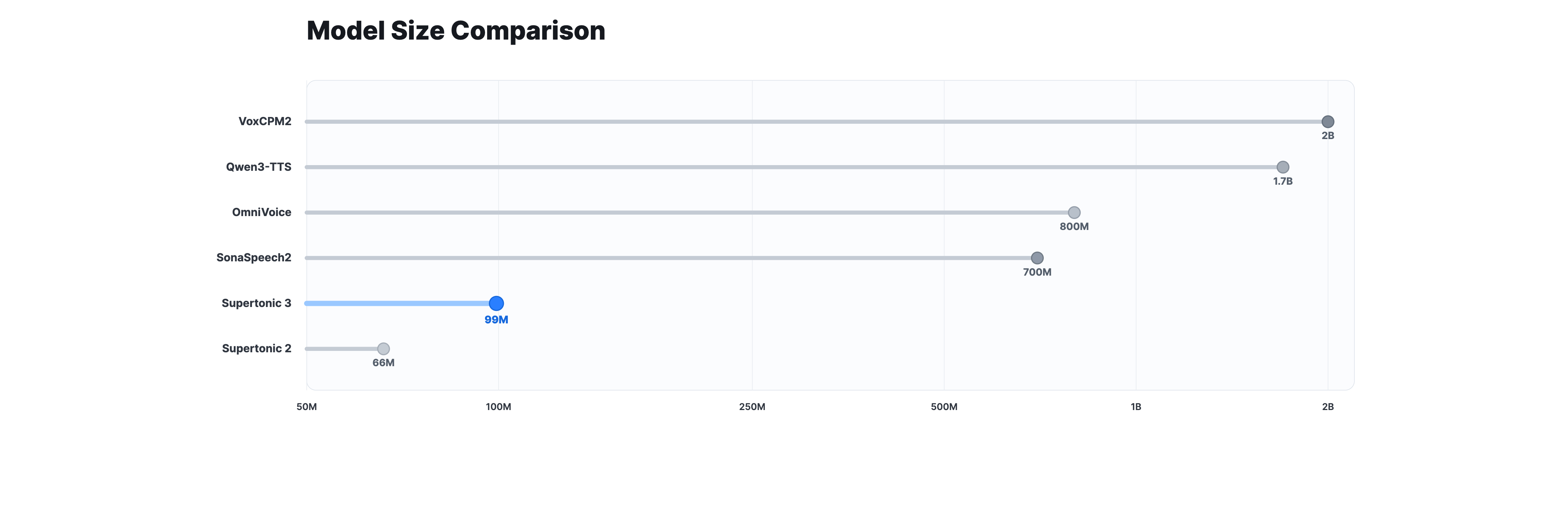
- 多语言原生支持:项目内置了多种语言的预训练模型,用户无需自行训练或转换。根据README,其模型大小在50-200MB之间,远小于云端模型。
与Coqui TTS(Python)或eSpeak(C++)相比,Supertonic的集成成本极低——只需添加一个Swift Package依赖。
谁应该用它
- iOS/macOS应用开发者:需要为App添加语音合成功能,但希望避免网络请求和隐私合规问题。例如,阅读器App的“朗读”功能、导航App的语音播报。
- 独立开发者:构建原型或小工具时,希望快速集成TTS而不想搭建后端。
- 边缘计算场景:在树莓派或Apple Silicon设备上运行离线语音助手。
局限与开放问题
目前Supertonic仍处于早期阶段:语音自然度与云端方案(如Azure TTS)尚有差距,尤其在情感表达和韵律控制方面。此外,模型仅提供有限的几种声音选项,且自定义声音需要额外训练流程。项目文档目前以英文为主,多语言使用示例尚不充分。
"在云端TTS成本高企、隐私监管趋严的当下,设备端语音合成迎来新选择。"
"Supertonic的集成成本极低——只需添加一个Swift Package依赖。"
"它试图证明:设备端语音合成可以既快又好。"
核心亮点
数据来源:TrendForge 历史采集
项目截图

今天Supertonic爆发主要源于社交媒体传播:一条在M1 Mac上实时合成语音的演示视频在Twitter和Reddit上被广泛转发,同时Hacker News上的讨论也带来大量流量。此外,苹果在WWDC前后对设备端AI的强调,使得Swift生态中的此类项目获得更多关注。项目本身在过去11天已积累5879星,说明其持续受到开发者认可。
iOS/macOS应用开发者,需要为App添加离线语音合成功能,例如阅读器、导航、无障碍工具等场景。也适用于独立开发者快速构建原型,以及边缘计算设备上的语音助手开发。
Supertonic选择ONNX Runtime而非Core ML,降低了模型转换门槛,并利用ONNX的CPU优化实现无GPU设备的高效推理。其多语言模型采用端到端架构,输出波形而非频谱,减少了后处理步骤。与Coqui TTS相比,Supertonic的Swift原生接口使集成更简单;与eSpeak相比,自然度显著提升。但模型大小(50-200MB)对某些轻量场景可能仍偏大。
语音自然度不及云端方案,情感表达有限;目前仅提供少数预设声音,自定义声音需额外训练;项目仍处于早期,文档和示例以英文为主,多语言支持细节有待完善。
使用场景
Supertonic 在设备端本地运行,无需网络或API调用,隐私安全且响应迅速。
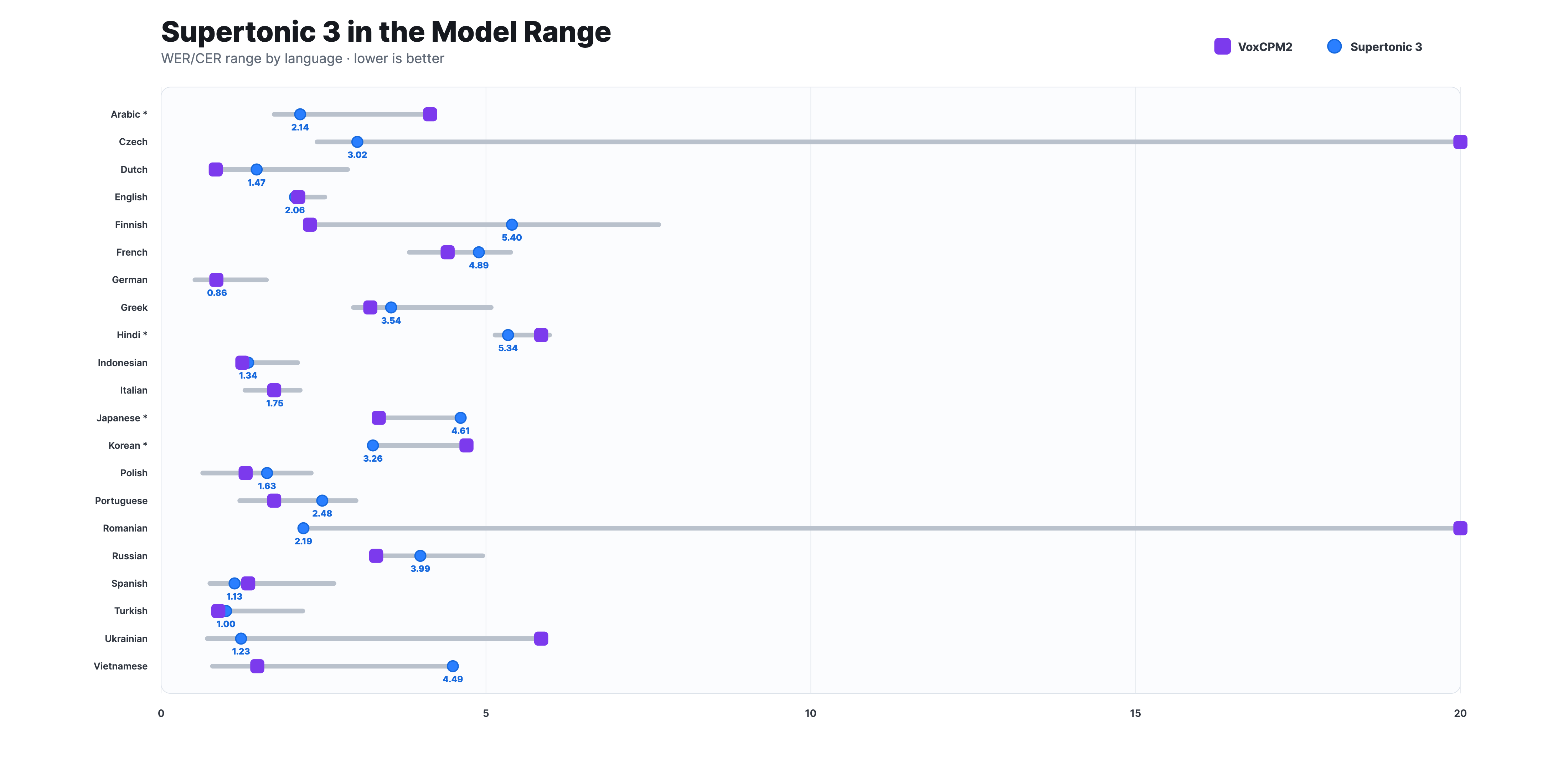
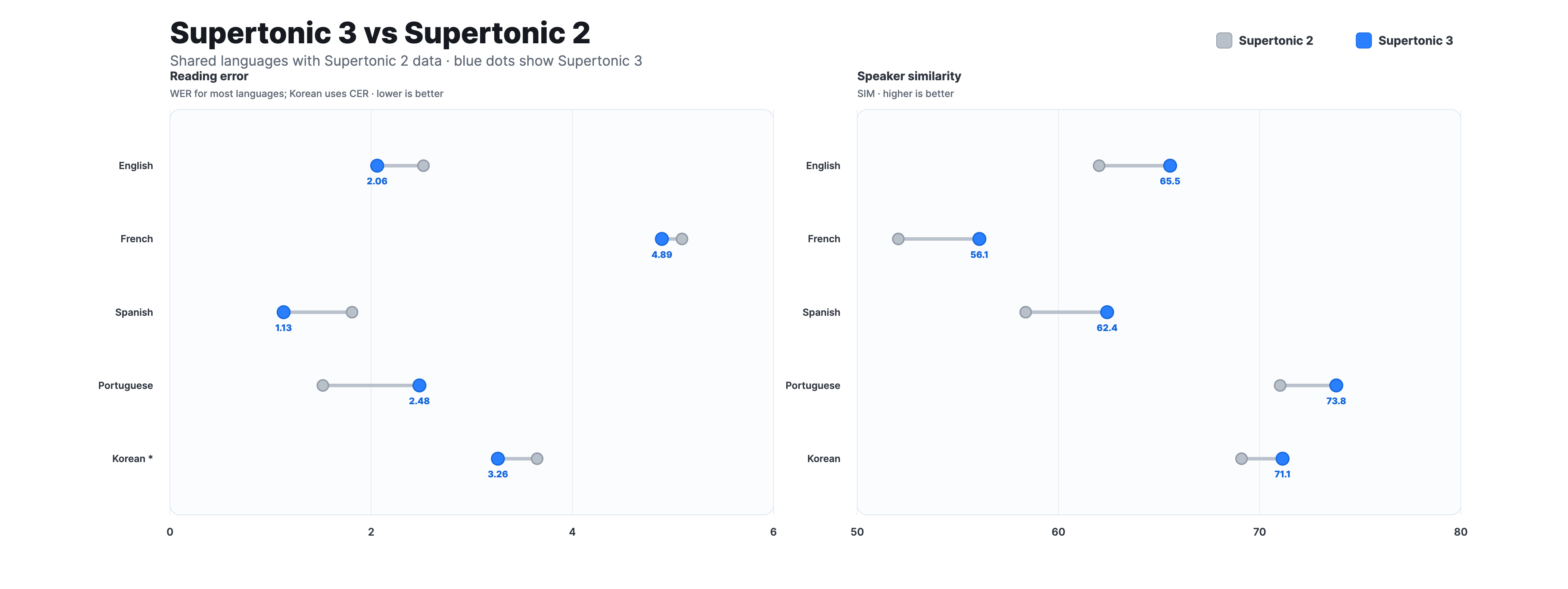
Supertonic 3 支持31种语言,通过ONNX原生执行,一套模型即可覆盖多语言需求。
Supertonic 提供Python、Swift、Node.js、Go、Java等十余种SDK,一套模型跨平台运行。
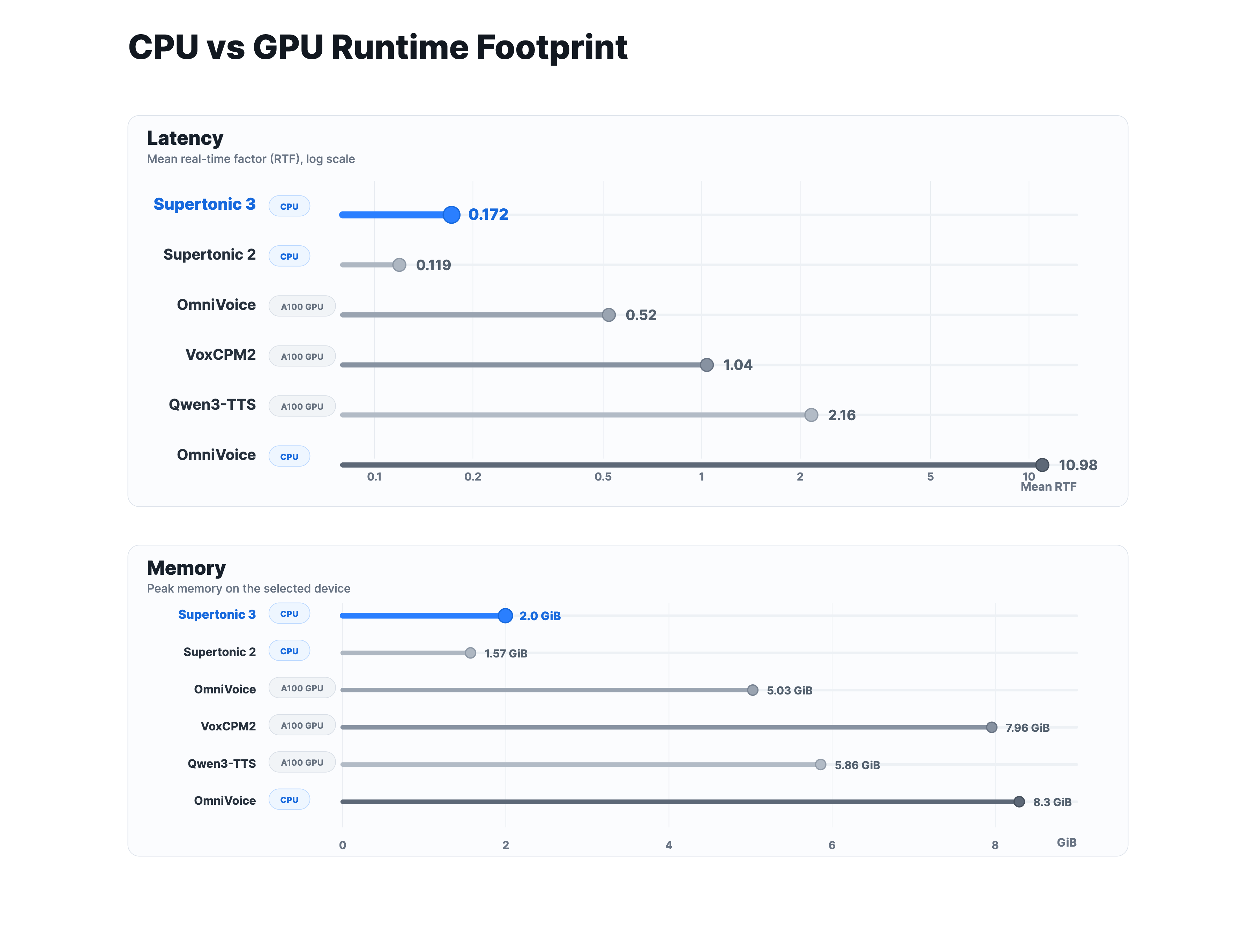
Supertonic 设备端推理速度极快,支持批处理,适合实时场景。
