当大模型还在比拼参数和对话能力时,一个名为 MiroFish 的开源项目悄然走红,它试图用群体智能模拟来“预测万物”。该项目在 16 天内狂揽 58,325 颗星,单日峰值高达 42,611,成为 GitHub 上罕见的现象级项目。MiroFish 并非简单的 AI 工具,而是一个构建数字平行世界的引擎——用户输入新闻、财报甚至小说章节,系统便会生成成千上万个拥有独立记忆和个性的智能体,让它们自由交互,推演事件的多重走向。这种“上帝视角”的模拟能力,让金融预测、舆情推演、创意生成等场景看到了新的可能性。
这个项目在做什么
MiroFish 试图解决一个古老而棘手的问题:如何预测复杂系统的未来?传统方法要么依赖统计模型(如时间序列预测),要么依赖专家判断,但两者都难以捕捉个体互动产生的涌现效应。MiroFish 的方案是:构建一个高保真的数字平行世界,让智能体在其中自主演化。
用户只需提供“种子”信息——可以是新闻、政策草案、财报,甚至是《红楼梦》前 80 回文本——MiroFish 会自动提取实体、关系,构建知识图谱,并为每个角色生成带有记忆和性格的智能体。随后,这些智能体在模拟环境中自由交互,系统记录并分析其行为,最终生成预测报告。用户还可以与模拟世界中的任意智能体对话,追问其决策逻辑。
这种“模拟-推演-交互”的闭环,将预测从黑箱输出变成了可追溯、可干预的沙盘实验。
为何此刻被关注
MiroFish 的爆发并非偶然。2026 年 3 月 31 日,项目单日新增 42,611 颗星,主要推手是社交媒体上的病毒式传播——一段展示“武汉大学舆情推演”的演示视频在 X 平台获得数百万播放。视频中,MiroFish 模拟了高校争议事件中不同群体的反应,并生成舆情演变报告,其逼真程度让观众惊叹。
更深层的原因在于,AI 社区对“下一代应用”的渴望。大语言模型的能力已经足够强大,但如何将其转化为解决实际问题的工具,仍是痛点。MiroFish 提供了一个极具想象力的范式:不是让 AI 直接回答问题,而是让 AI 构建一个世界,让答案在其中自然浮现。这种“世界模拟器”的定位,恰好踩中了技术社区对 AGI 路径的讨论热点。
此外,项目在 README 中提供了详细的快速开始指南,支持源码和 Docker 部署,降低了体验门槛。GitHub 上的 9,760 个 fork 也表明,开发者正在积极尝试二次开发。
技术上有何不同
MiroFish 的核心技术栈包括多智能体系统、知识图谱(GraphRAG)和动态记忆更新。与同类项目相比,它的差异化在于:
- 与 AutoGen / CrewAI 对比:这些框架专注于让 AI 代理协作完成任务(如编码、写作),而 MiroFish 的目标是模拟社会系统。它的智能体不仅执行指令,还拥有“人格”和长期记忆,行为更接近真实人类。
- 与 Simulacra(斯坦福虚拟小镇)对比:Simulacra 开创了生成式智能体的概念,但仅限于封闭的虚拟环境。MiroFish 允许用户注入任意现实数据,并提供了完整的预测报告生成和交互接口,实用性更强。
- 与 LangChain 对比:LangChain 是 LLM 应用的编排工具,而 MiroFish 是更高层的模拟引擎。它内置了实体关系提取、角色生成、环境搭建等模块,用户无需编写复杂流程。
一个值得注意的设计是“双平台并行模拟”:MiroFish 同时运行两个模拟实例,一个用于生成结果,另一个用于验证稳定性,这种冗余机制在预测类应用中至关重要。
谁应该用它
- 金融分析师:输入财报或宏观新闻,模拟不同投资者群体的反应,预测股价短期波动和舆论焦点。例如,某科技巨头发布低于预期的 Q2 财报后,MiroFish 可推演散户、机构、做空者的行为,生成情绪曲线和价格区间。
- 企业公关团队:在危机事件爆发后,输入事件通报和初始社交媒体数据,模拟消费者、媒体、监管部门的互动,预测舆论演变路径和风险点。README 中引用的“武汉大学舆情推演”即为典型场景。
- 作家与编剧:将小说前文或大纲输入,让角色在模拟世界中自由交互,推演符合人设的后续情节。README 展示了基于《红楼梦》前 80 回推演失传后文的案例,为创作者提供灵感。
- 政策制定者:输入政策草案和人口数据,模拟不同利益相关者的长期行为调整,评估政策效果。例如,模拟“某城市拟征收拥堵费”对交通流量、商业活力、公众满意度的影响。
局限与开放问题
尽管 MiroFish 令人兴奋,但它并非万能。首先,模拟的保真度高度依赖种子数据的质量和智能体人格设计的合理性——如果输入偏差,输出也会偏差。其次,当前版本仅支持 Python 后端和 Node.js 前端,对于非技术用户仍有门槛。此外,大规模模拟(如百万级智能体)的计算成本尚未公开,可能限制其应用范围。最后,项目仍处于早期阶段,文档中提到的“金融预测”和“政治新闻预测”示例尚未发布,实际效果有待验证。
"不是让 AI 直接回答问题,而是让 AI 构建一个世界,让答案在其中自然浮现。"
"MiroFish 将预测从黑箱输出变成了可追溯、可干预的沙盘实验。"
"让每一个'如果'都能看到结果——预测万物,从严肃推演到趣味模拟。"
核心亮点
数据来源:TrendForge 历史采集
项目截图


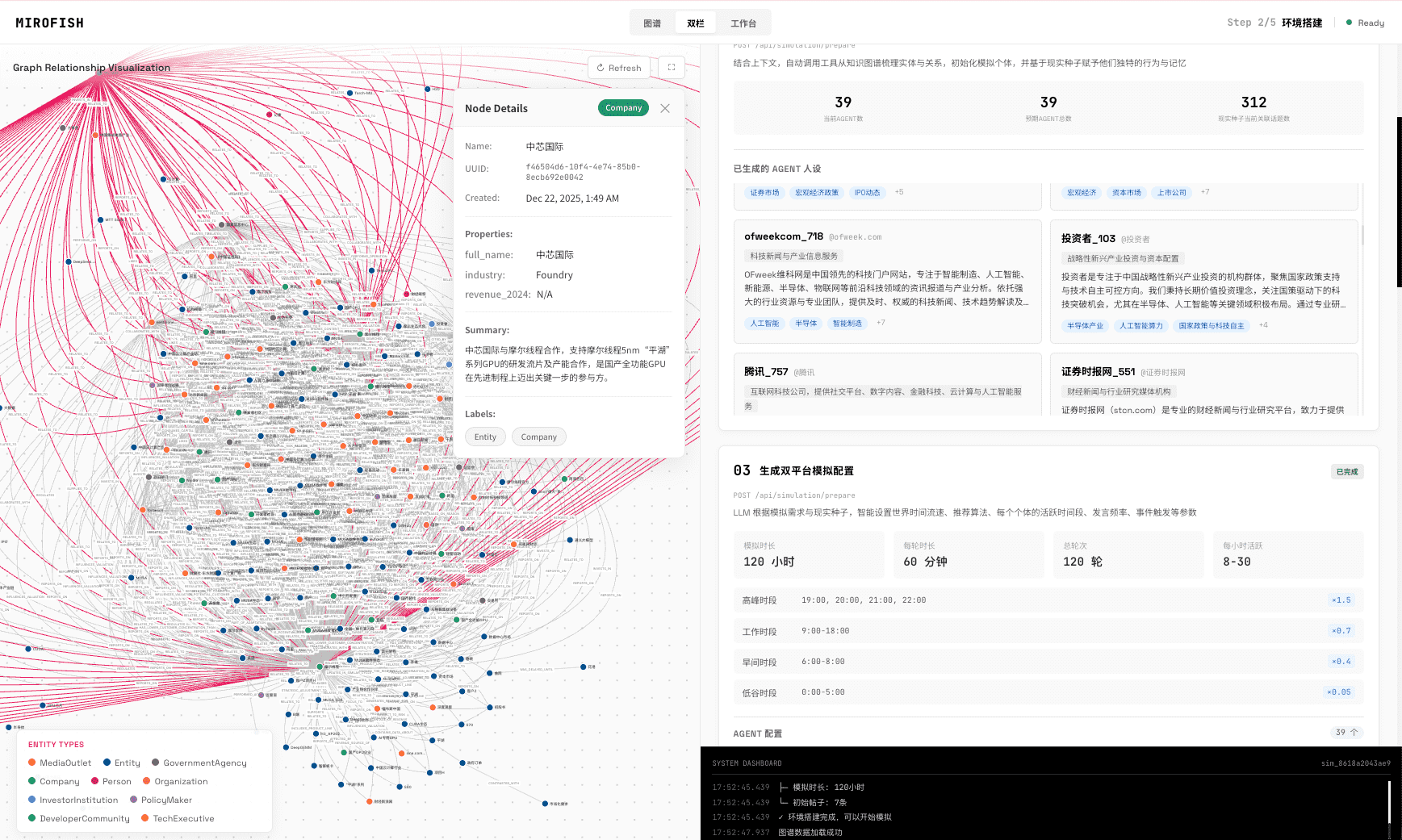
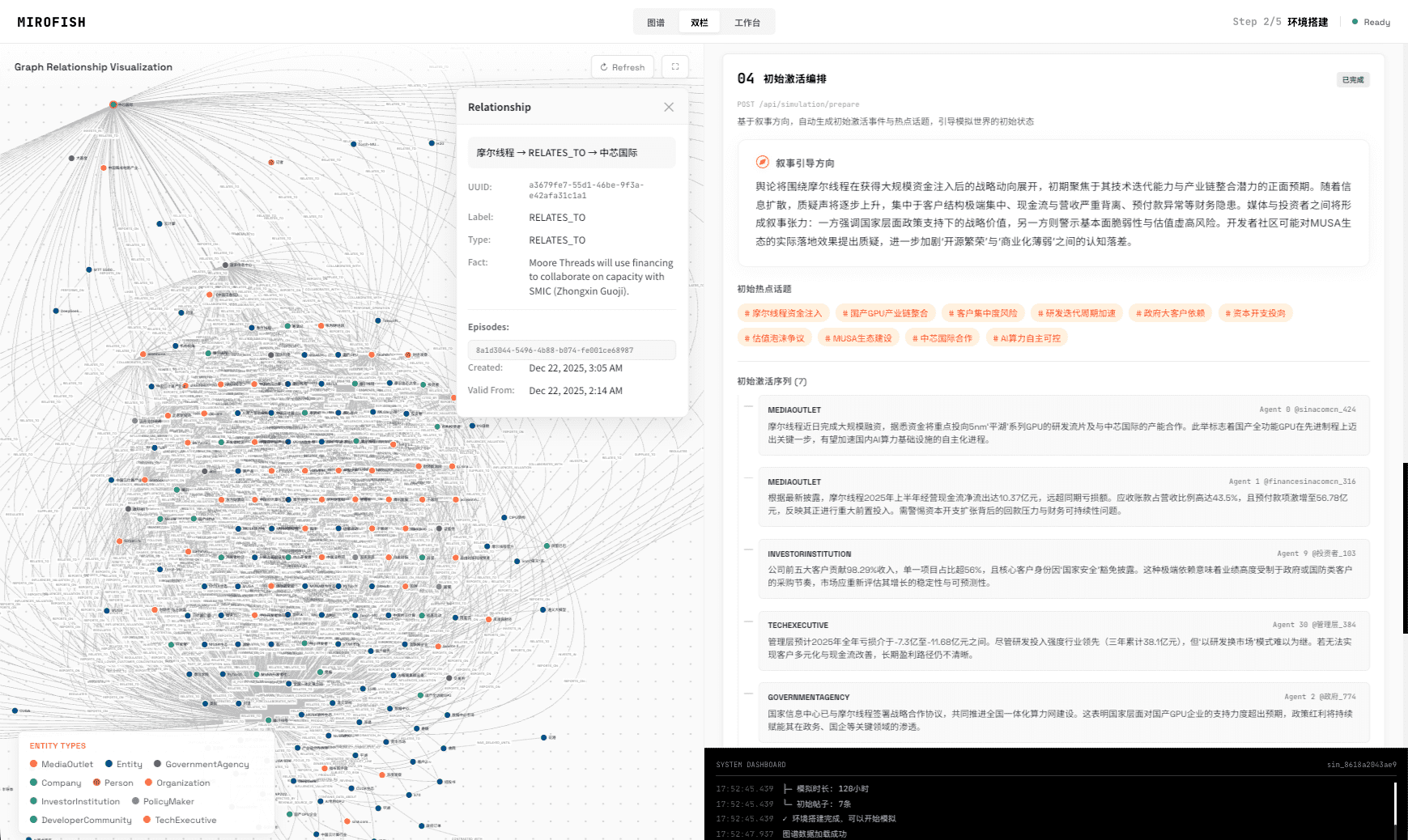
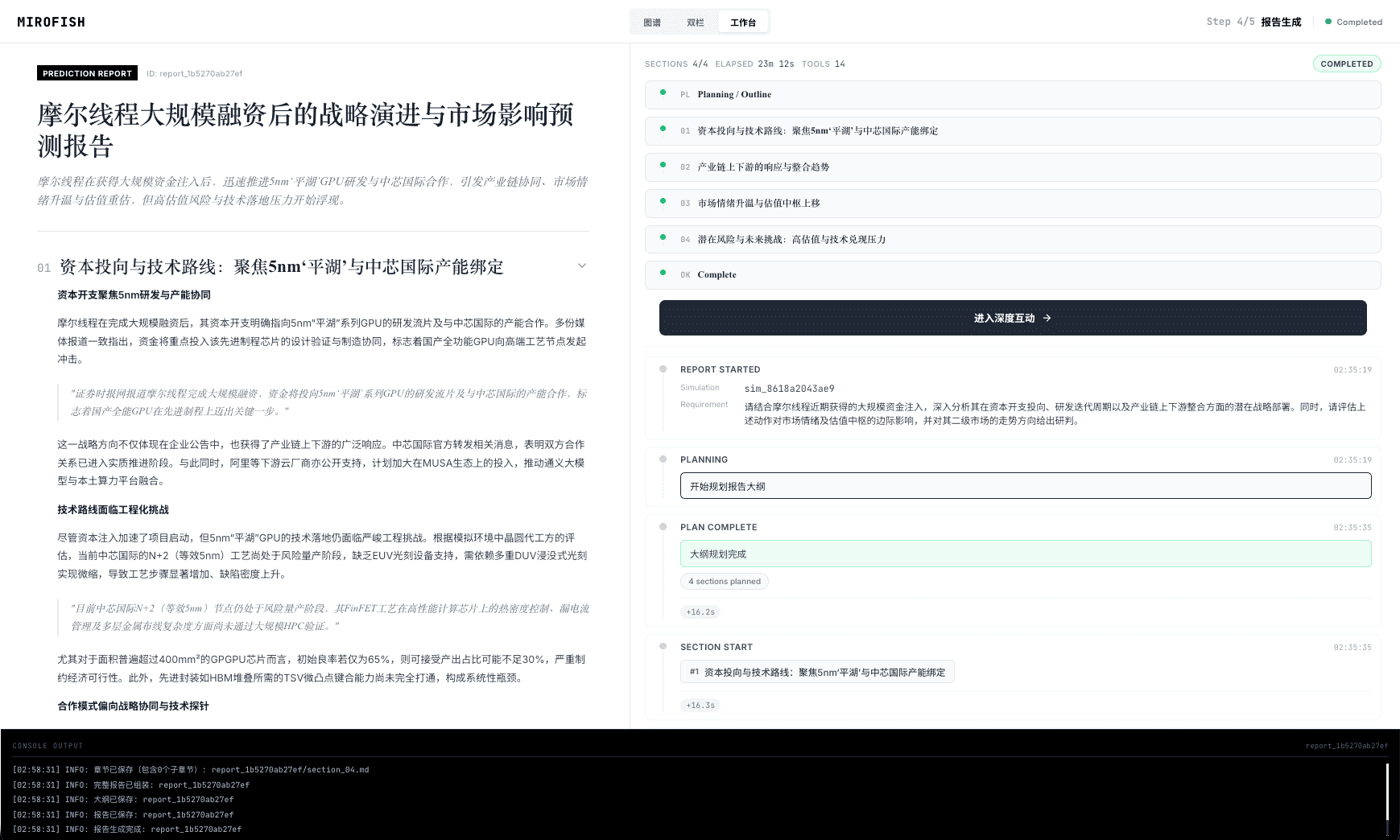
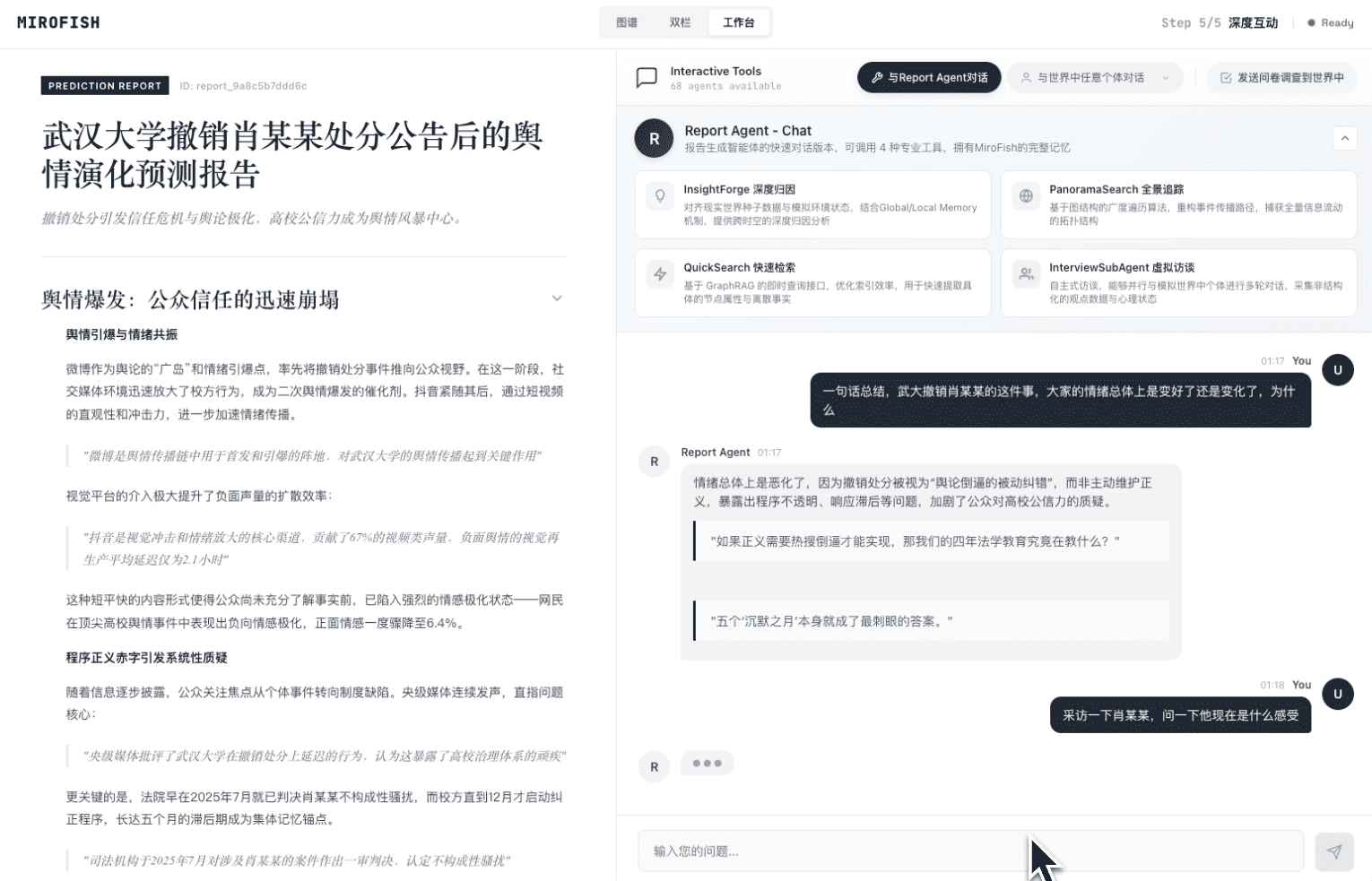
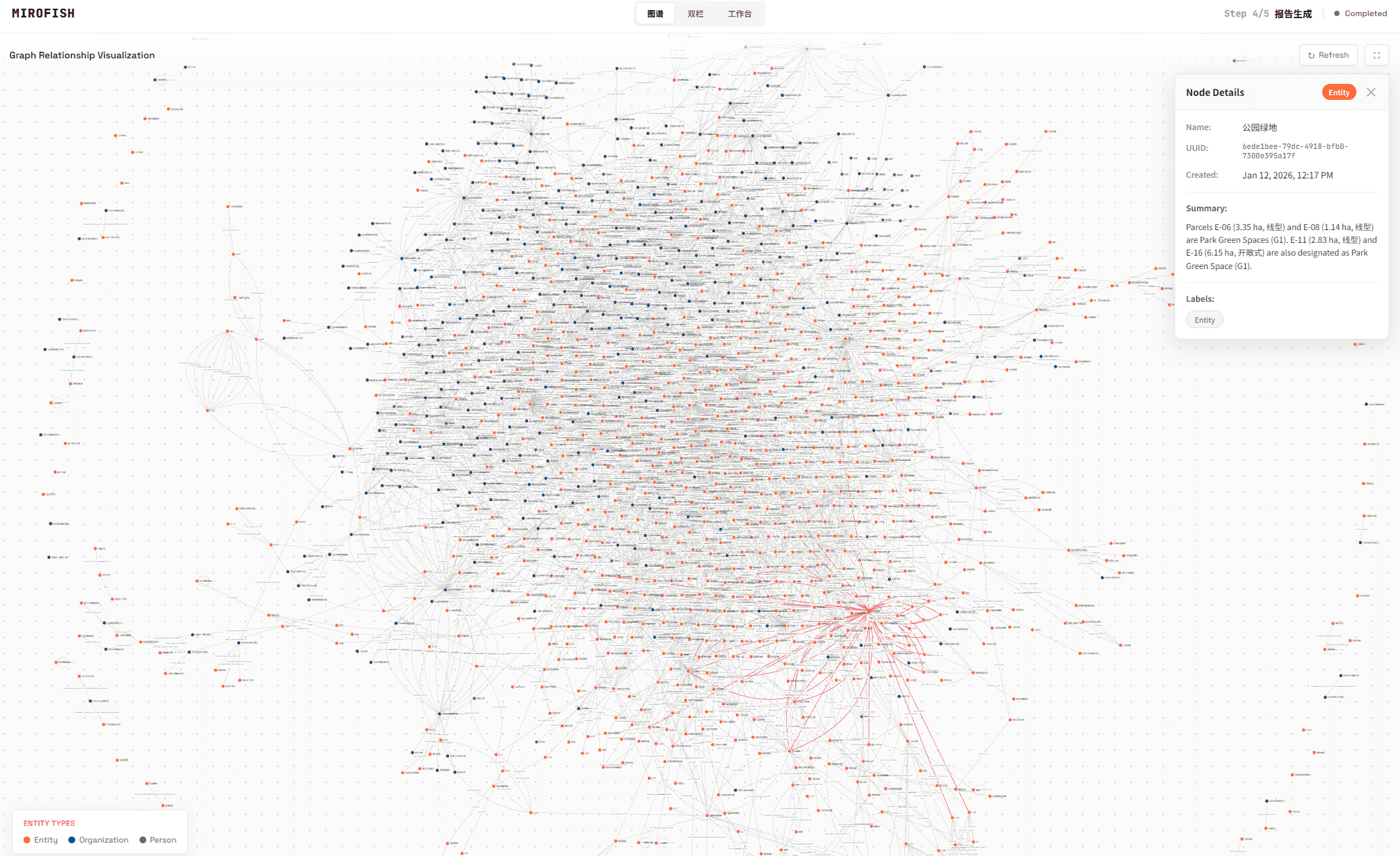
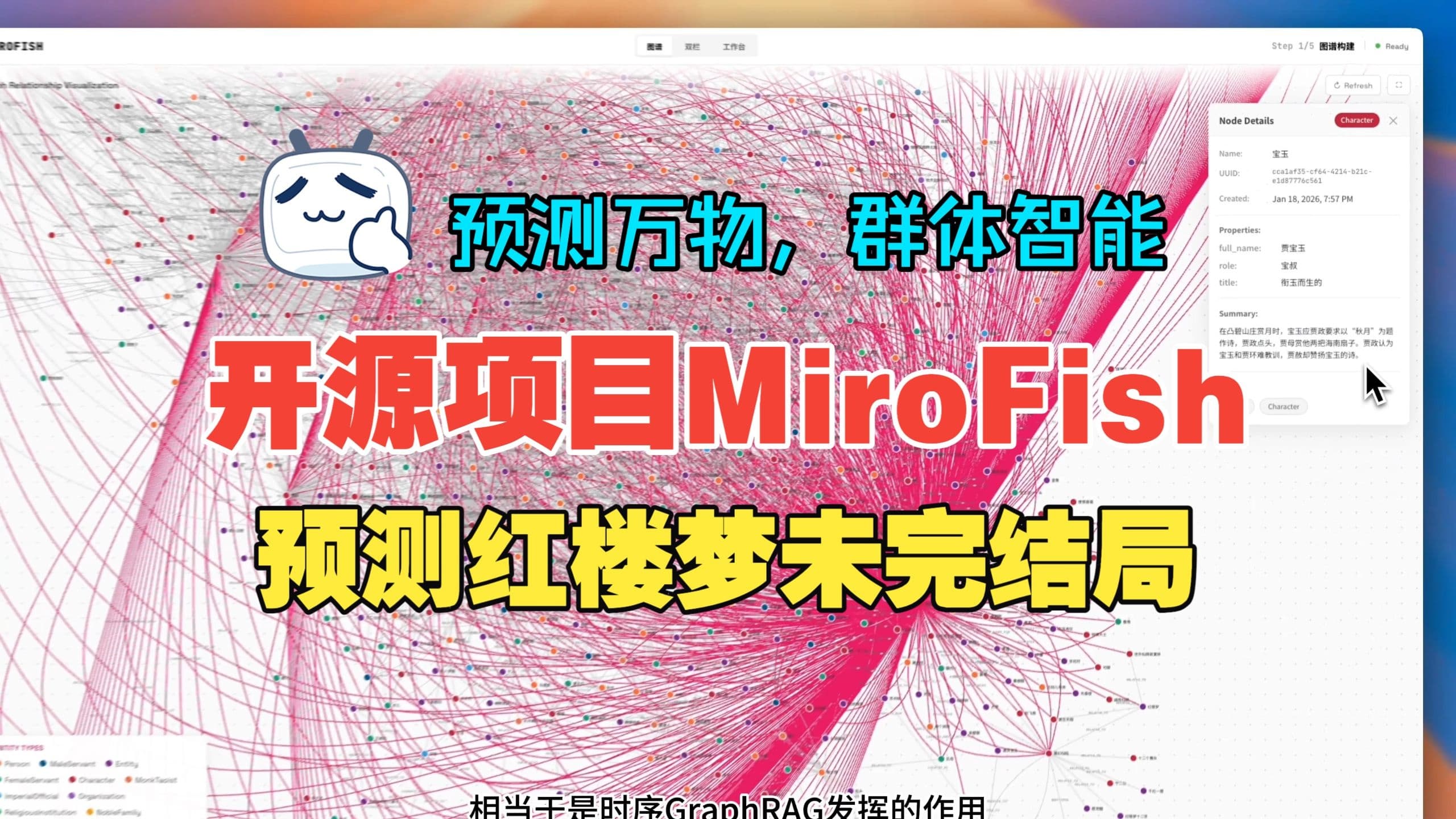


2026 年 3 月 31 日,一段展示 MiroFish 模拟“武汉大学舆情推演”的演示视频在 X 平台病毒式传播,单日播放量超数百万,直接带动项目单日新增 42,611 颗星。此外,项目踩中了 AI 社区对“世界模拟器”范式的期待,其“预测万物”的口号极具传播力。GitHub 上 9,760 个 fork 也表明开发者正在积极尝试二次开发,形成社区自传播。
金融分析师(预测市场情绪)、企业公关团队(舆情危机推演)、作家/编剧(故事结局推演)、政策制定者(政策效果沙盘模拟)。这些角色需要低成本、高保真的模拟工具来辅助复杂决策,且具备一定的技术基础或团队支持。
MiroFish 的核心创新在于将多智能体系统与知识图谱(GraphRAG)结合,实现从种子信息到动态平行世界的自动化构建。其双平台并行模拟设计(一个实例生成结果,另一个验证稳定性)在预测类应用中独树一帜。与 AutoGen 等代理框架不同,MiroFish 的智能体拥有长期记忆和人格参数,行为更接近真实人类。但项目仍依赖外部 LLM API(如 OpenAI),且大规模模拟的计算效率尚未公开。
模拟保真度依赖种子质量和人格设计,存在偏差风险;当前仅支持 Python/Node.js,非技术用户门槛高;大规模模拟计算成本未知;部分示例(金融预测)尚未发布,实际效果待验证。
使用场景
将新闻、财报等作为“种子”输入MiroFish,引擎会自动创建代表不同投资者类型的智能体,模拟他们在数字世界中的互动和决策,推演市场情绪和价格走势。
将事件通报、社交媒体初始反应等作为种子,MiroFish构建包含消费者、媒体、竞争对手、监管部门等多方角色的平行世界,推演舆论发酵、转移或升级的多种可能性。
将小说前文或故事大纲作为种子输入,MiroFish为每个角色注入记忆与性格,让他们在模拟世界中自由交互,从而推演出符合逻辑的后续情节或多种分支结局。
输入“某城市拟征收拥堵费”的政策草案和交通数据,模拟私家车主、公交公司、商圈、通勤者等群体的长期行为调整,预测对交通流量、商业活力、公众满意度的影响。
