今天,OpenBMB 正式开源 VoxCPM2,一个 2B 参数、支持 30 种语言、可语音设计、可控克隆的端到端 TTS 模型。单日 GitHub Stars 增长超 1800,背后是社区对“无分词器”架构和 48kHz 高清输出的强烈反响。它能否像 Whisper 之于 ASR 一样,定义开源 TTS 的新标准?
这个项目在做什么
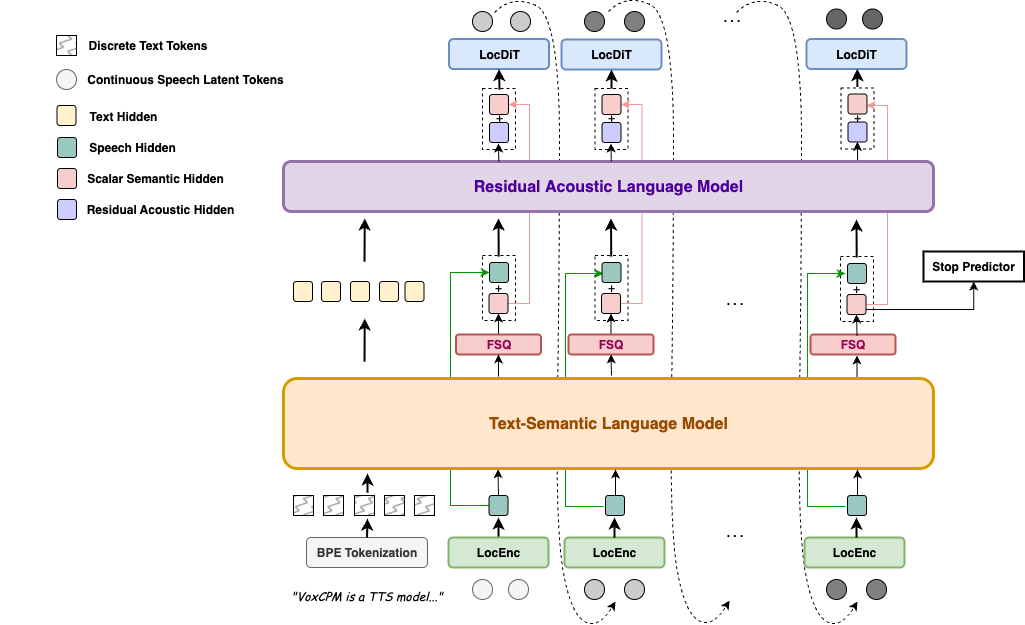
VoxCPM 是一个“无分词器”(tokenizer-free)的文本转语音系统。传统 TTS 需要先将音频离散化为 token,再通过 vocoder 合成,而 VoxCPM 直接生成连续的语音表征,绕过了离散化带来的信息损失。V2 版本基于 MiniCPM-4 骨干网络,训练数据超过 200 万小时,支持 30 种语言和多种中文方言。
核心能力有三:
- 语音设计:仅凭自然语言描述(如“一位 30 岁男性,语速稍快,带点兴奋”)即可生成全新声音,无需任何参考音频。
- 可控克隆:从短参考音频中克隆音色,并可通过风格引导控制情感、语速等。
- 终极克隆:提供参考音频及其文本,模型能无缝延续,保留所有声音细节。
为何此刻被关注
本期新增 1,815 Stars,单日峰值曾达 4,136。爆发点很明确:2026 年 4 月 19 日 VoxCPM2 正式发布,同时开放了权重、文档和在线 Playground。社区在 Reddit、Twitter 上大量讨论,尤其是“语音设计”功能——无需参考音频即可创造新声音,这在开源 TTS 中极为罕见。
此外,项目提供了 Nano-vLLM 和 vLLM-Omni 两种生产级推理方案,RTF 低至 0.13(RTX 4090),并支持 OpenAI 兼容 API。这意味着开发者可以像调用 GPT-4o 一样调用 VoxCPM2,大幅降低了部署门槛。
技术上有何不同
与 Coqui TTS、XTTS 等主流开源方案相比,VoxCPM2 的“无分词器”设计是根本差异。XTTS 使用离散化 token,在音色克隆时容易出现“机械感”;而 VoxCPM 的连续表征能保留更多自然韵律。
另一个亮点是 AudioVAE V2 的非对称编解码设计:接受 16kHz 参考音频,直接输出 48kHz 高质量音频,内置超分辨率。这省去了外挂 upsampler 的麻烦,也减少了级联误差。
在可控性上,VoxCPM2 的“语音设计”功能类似 ElevenLabs 的 Voice Design,但完全开源。用户只需写一段描述,模型就能生成符合描述的声音,这为创意内容生产打开了新空间。
谁应该用它
- 语音应用开发者:需要快速集成多语言 TTS 到产品中,尤其是需要定制声音(如虚拟主播、有声书)的场景。VoxCPM2 的 OpenAI 兼容 API 和低 RTF 使其适合生产部署。
- 内容创作者:播客、视频配音、游戏角色配音等。语音设计功能允许他们创造独特声音,无需雇佣配音演员。
- 研究者:对端到端 TTS、无分词器架构感兴趣的研究人员。项目完全开源,可在此基础上微调或改进。
局限与开放问题
尽管 VoxCPM2 令人印象深刻,但仍有不足:
- 中文方言支持有限:虽然列出了 9 种方言,但实际效果可能不如标准普通话稳定。
- 长文本合成:目前未明确说明最大音频时长,长文本可能面临上下文窗口限制。
- 计算资源:2B 参数模型在消费级 GPU 上实时运行需要 RTX 4090 级别,低端设备无法本地部署。
- 伦理风险:语音克隆技术可能被滥用,项目虽开源但未内置水印或检测机制。
"VoxCPM2 绕过了离散化 token 的信息损失,这是它与众不同的核心。"
"语音设计功能让任何人都能成为声音设计师,无需录音棚。"
"它可能成为 TTS 领域的 Whisper——开源、多语言、可商用。"
核心亮点
数据来源:TrendForge 历史采集
项目截图

VoxCPM2 于 2026 年 4 月 19 日发布,恰逢社区对高质量开源 TTS 的渴求。其“语音设计”功能在社交媒体上引发病毒式传播,许多创作者展示了用文字描述生成的声音片段。同时,项目提供了生产级推理方案(Nano-vLLM、vLLM-Omni),让开发者能快速集成,进一步推动了 Stars 增长。
语音应用开发者(需集成多语言 TTS 到产品)、内容创作者(播客、视频配音)、AI 研究者(端到端 TTS 方向)。具体场景:虚拟主播声音定制、有声书自动生成、游戏角色配音、多语言客服语音。
VoxCPM2 的核心创新在于无分词器架构,使用扩散自回归模型直接生成连续语音表征,避免了离散化带来的量化误差。AudioVAE V2 的非对称编解码设计(16kHz 输入,48kHz 输出)内置超分辨率,减少了级联模块。与 XTTS 相比,VoxCPM2 在音色克隆的自然度上更胜一筹,且支持语音设计这一独特功能。推理方面,借助 PagedAttention 和连续批处理,vLLM-Omni 实现了 0.13 的 RTF,接近实时。
中文方言效果可能不稳定;长文本合成上限未明确;2B 模型需要 RTX 4090 级别 GPU;缺乏内置水印或滥用检测机制,存在伦理风险。
