当大模型训练被普遍认为需要成百上千张GPU时,一个名为train-llm-from-scratch的开源项目却反其道而行之。它提供了一套从数据下载到文本生成的完整流水线,让开发者用单张消费级GPU(如RTX 3090)就能训练一个1300万参数的语言模型。今天,该项目单日新增626颗星,三天暴涨1420星,成为GitHub日榜焦点。这背后是AI民主化浪潮中一个具体而微的实践:降低门槛,但不牺牲教育意义。
这个项目在做什么
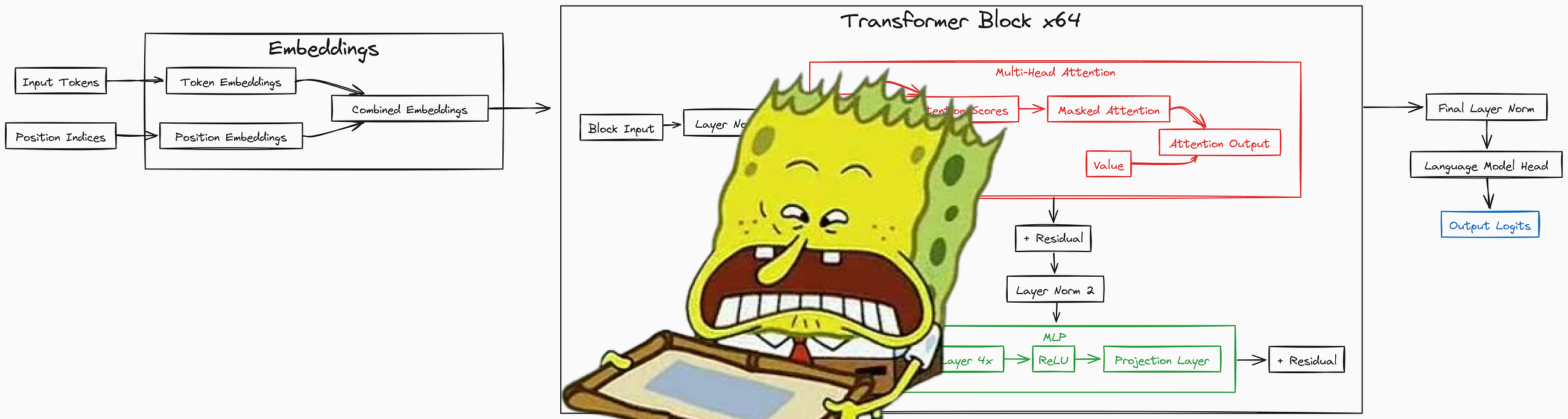
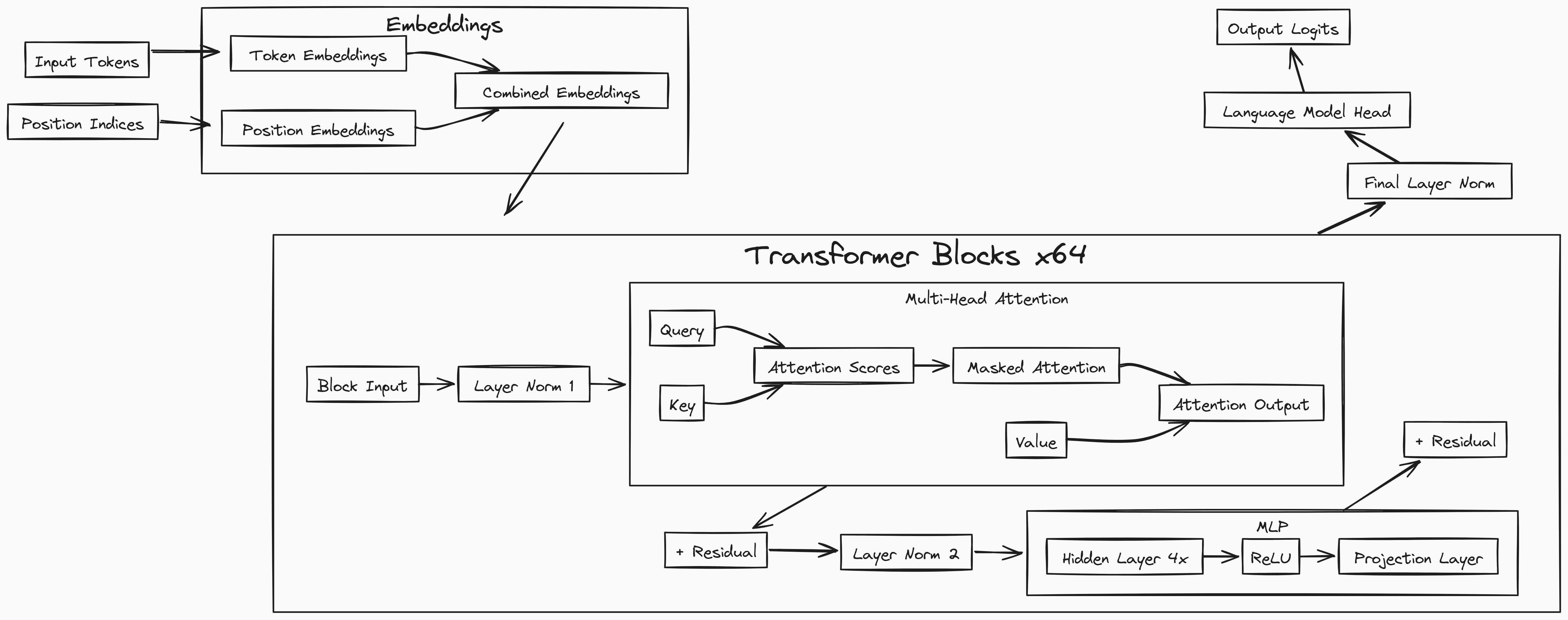
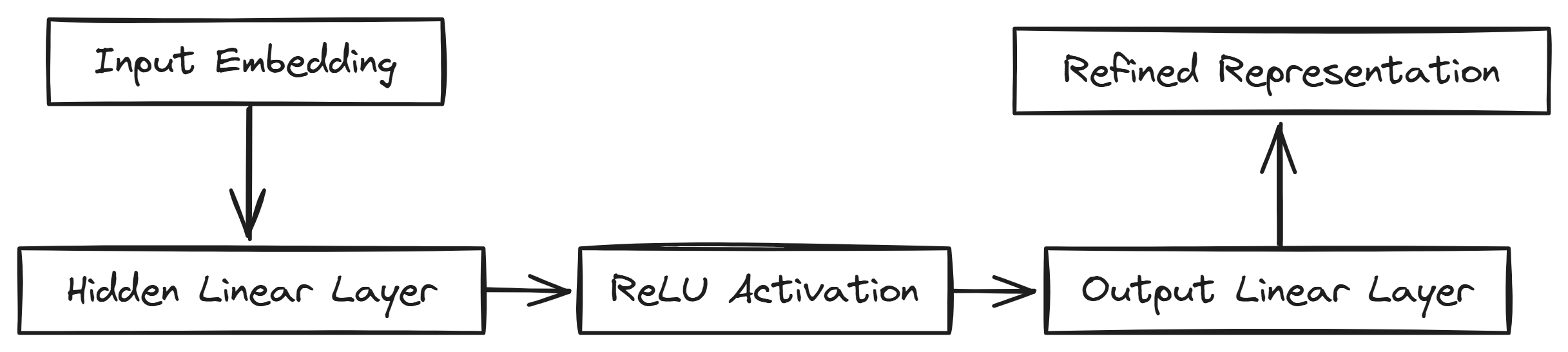
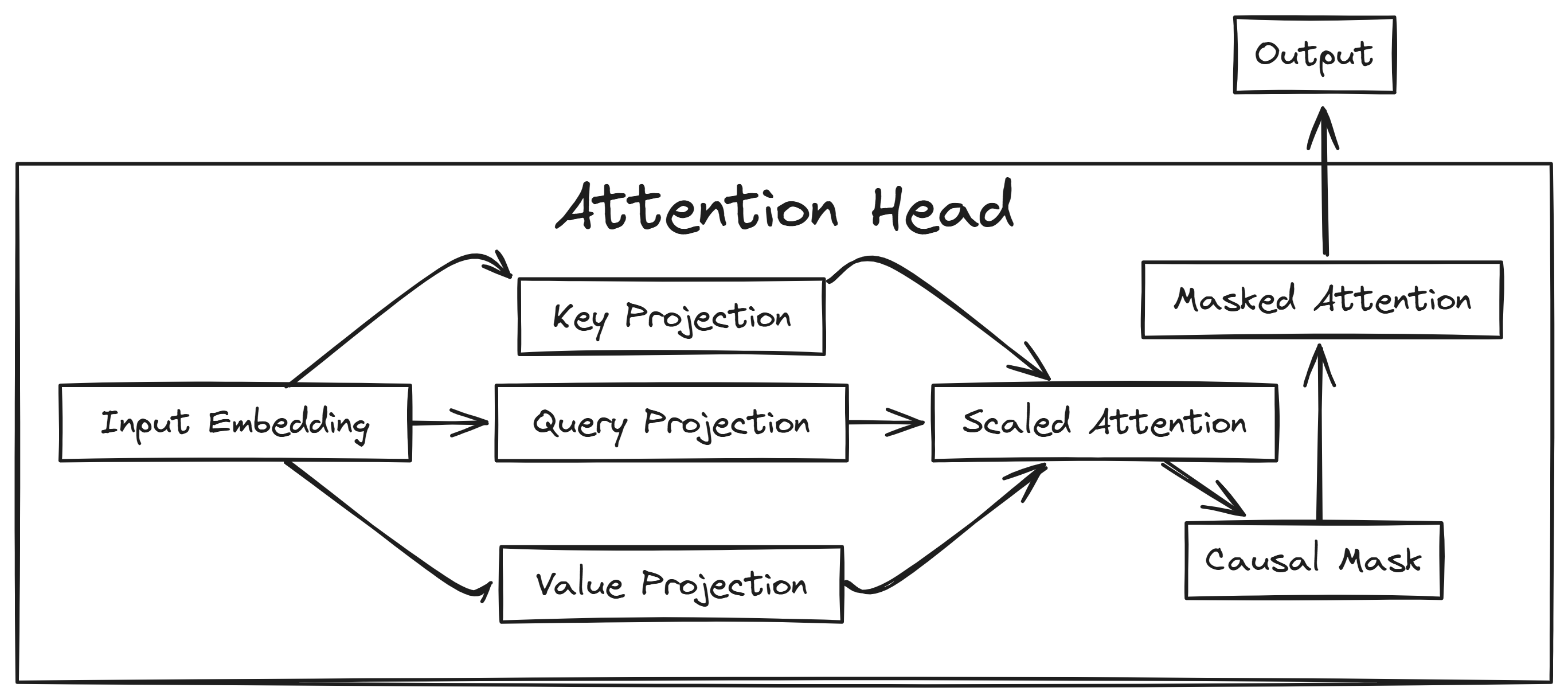
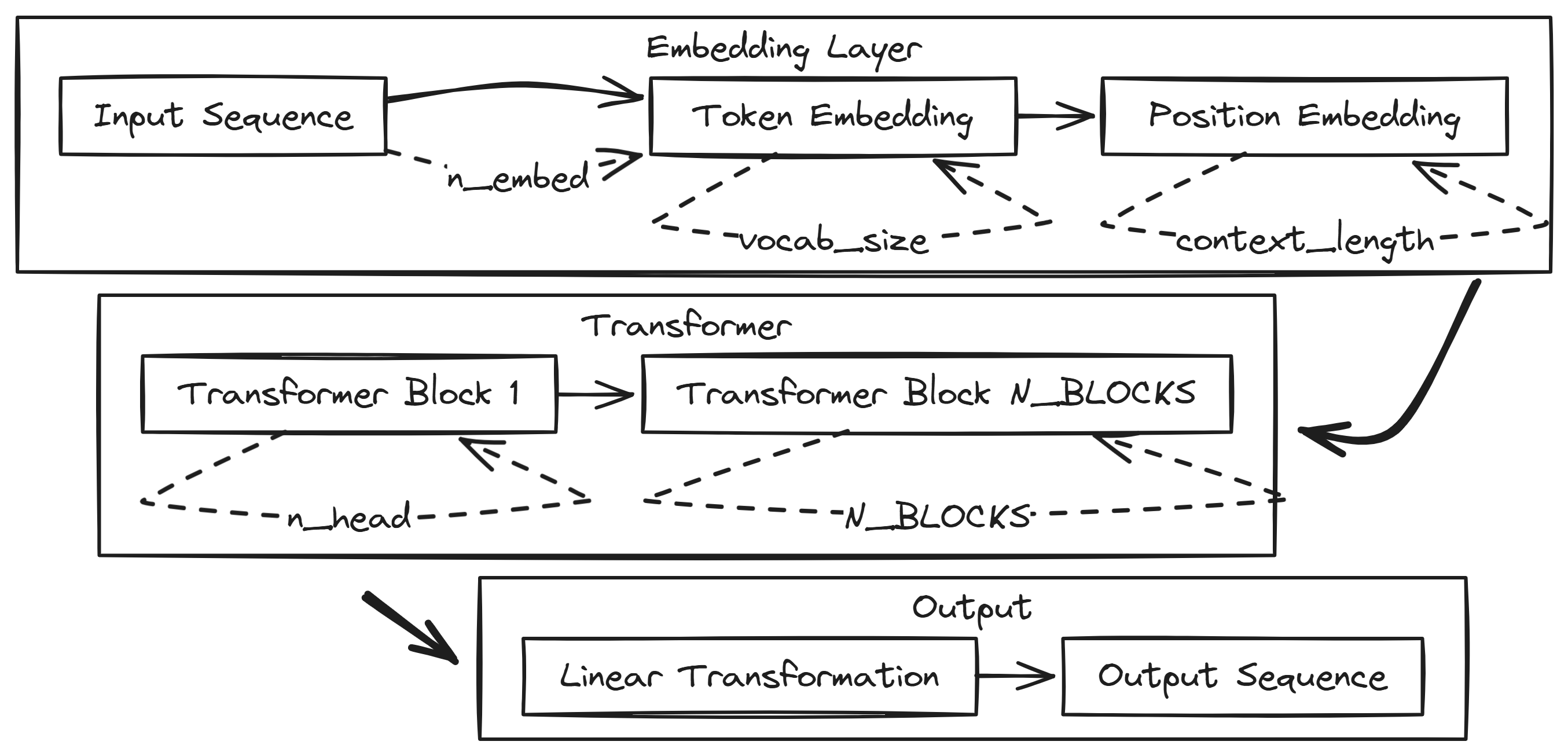
train-llm-from-scratch 不是一个开箱即用的聊天机器人框架,而是一份教学级的生产实现。它基于PyTorch,从零实现Transformer架构(遵循《Attention is All You Need》论文),并完整覆盖了数据准备、模型定义、训练循环、文本生成四个阶段。
核心价值在于:它把大模型训练从“黑盒API调用”拉回到“可理解的代码”。项目README中提供了逐行代码解释,并附带了OOP、神经网络、PyTorch的入门视频链接——这更像是一本互动教材,而非工具库。
为何此刻被关注
本期爆发并非因为某个新版本发布,而是社交媒体传播的连锁反应。项目作者FareedKhan-dev在Hacker News和Reddit的r/MachineLearning板块分享了自己的训练成果(一个13M参数模型生成的文本示例),引发了“单GPU训练LLM”话题的热议。
此外,当前AI领域正经历从“堆算力”到“提效率”的转向。Meta的LLAMA系列、Mistral等模型证明了小参数模型也能有不错表现,而train-llm-from-scratch恰好提供了亲手复现这种“小而美”路径的脚手架。
技术上有何不同
与类似项目(如nanoGPT、minGPT)相比,train-llm-from-scratch的差异化在于:
- 更完整的教学链:不仅提供模型代码,还包含了数据下载脚本(使用Pile数据集)、训练参数配置、损失曲线可视化,以及生成文本的示例。
- 硬件兼容性表格:项目详细列出了从GTX 1080 Ti到A100共15种GPU的训练可行性,甚至给出了最大可训练模型规模的估算(例如RTX 3090可训练约3.5B-4B参数模型)。这种透明度在同类项目中罕见。
- 单文件结构:代码集中在几个Jupyter Notebook中,降低了理解成本。相比之下,nanoGPT的代码分散在多个Python模块中,更适合作为生产基线而非教学起点。
谁应该用它
- AI/ML方向的学生:希望从理论走向实践,理解Transformer内部机制。项目提供了从零构建的完整代码,配合论文阅读效果更佳。
- 独立开发者或小团队:预算有限但想验证特定领域的小模型(如客服分类、代码补全)。单卡即可训练13M参数模型,成本可控。
- 技术写作者或教育者:需要一份可复现的教学案例来讲解LLM训练流程。
局限与开放问题
项目目前仅支持单GPU训练,且训练数据仅使用了Pile数据集的一小部分(未明确说明具体采样量)。对于希望训练更大规模模型(>1B参数)的用户,硬件门槛依然很高——表格显示,只有A100、RTX 8000等高端卡才能胜任2B模型训练。此外,项目未提供分布式训练或模型并行支持,这限制了其扩展性。
"训练自己的LLM不再是科技巨头的专利,单张消费级GPU就能起步。"
"这个项目把大模型训练从黑盒API调用拉回到可理解的代码。"
"它更像是一本互动教材,而非工具库。"
核心亮点
数据来源:TrendForge 历史采集
项目截图
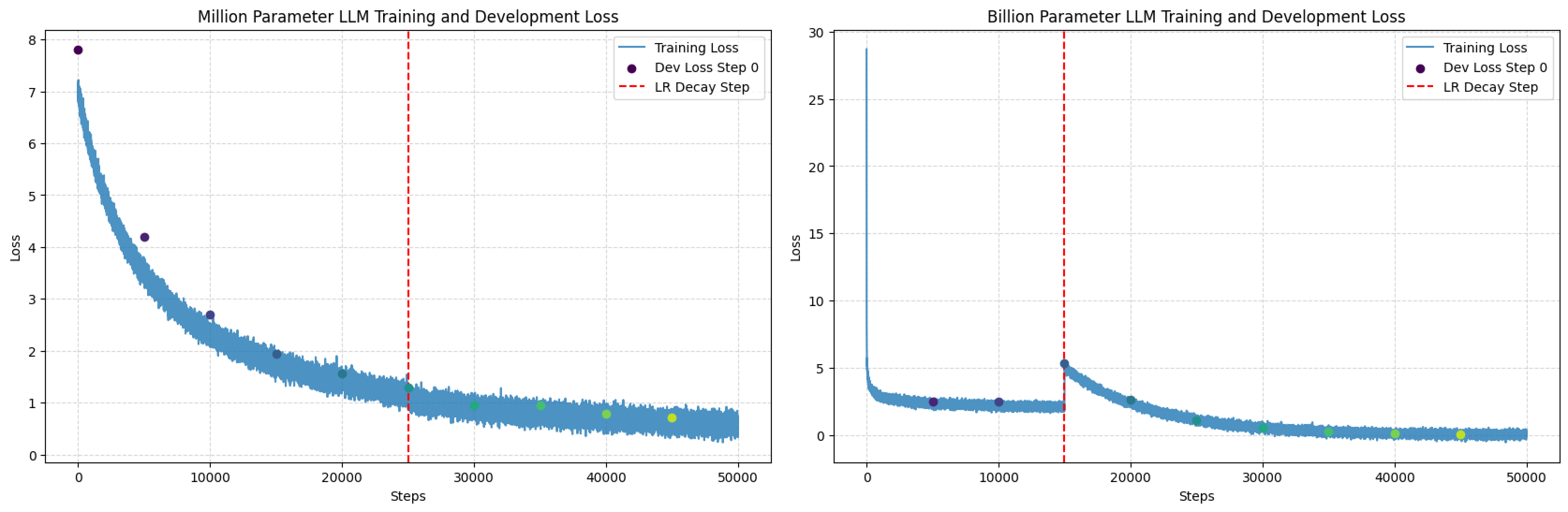
今天单日新增626星,近三天累计1420星,主要驱动力来自社交媒体传播。项目作者在Hacker News和Reddit的机器学习板块分享训练成果后,引发了‘单GPU训练LLM’话题的病毒式讨论。当前AI社区正关注小参数模型的高效训练,该项目恰好提供了可复现的路径。此外,项目README中详细的硬件兼容性表格和教学导向的代码结构,降低了非专业人士的尝试门槛,吸引了大量学生和独立开发者。
AI/ML方向的学生(用于理解Transformer实现)、独立开发者或小团队(预算有限但想训练特定领域小模型)、技术教育者(需要可复现的教学案例)。
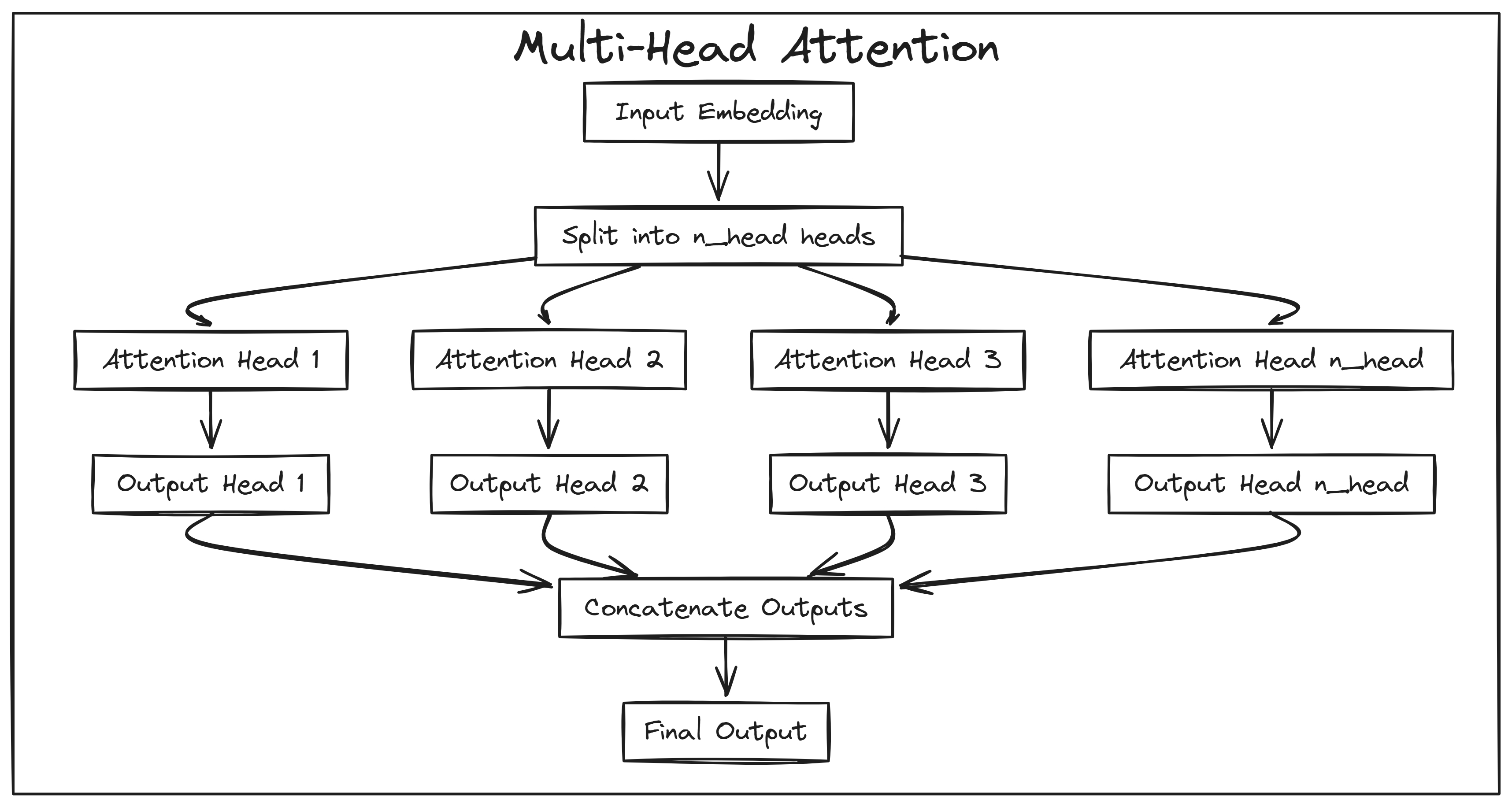
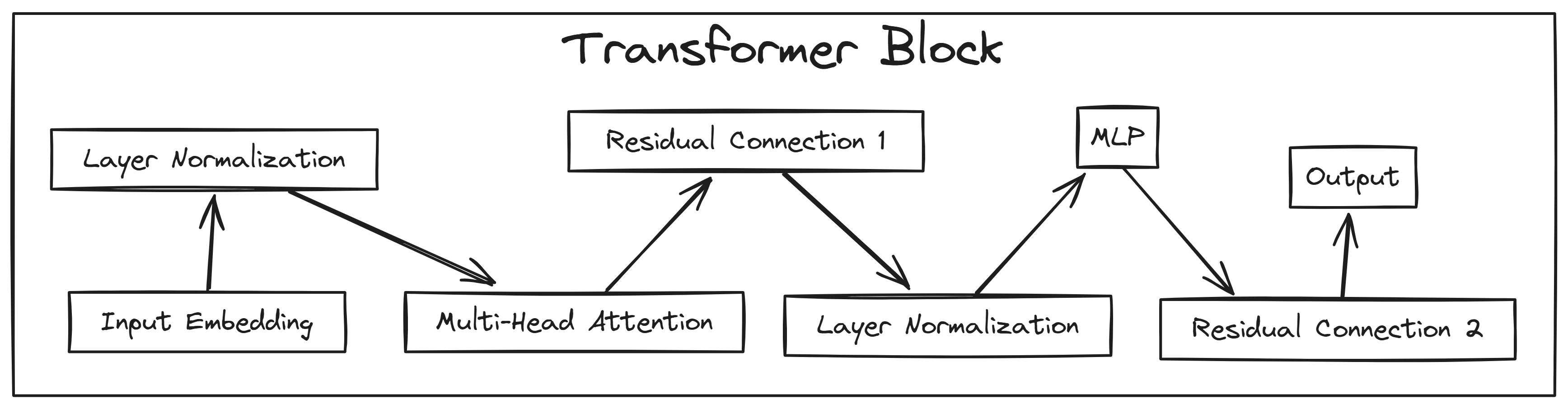
项目基于PyTorch,从零实现Transformer,核心设计选择包括:单头注意力机制(便于理解)、多层感知器(MLP)模块、以及完整的训练循环。与nanoGPT相比,该项目更强调教学性——代码集中在Jupyter Notebook中,并附有逐行解释。硬件兼容性表格是亮点,明确列出了不同GPU的最大可训练模型规模(如RTX 3090可训练约3.5B-4B参数),这种透明度在开源项目中少见。但项目未支持分布式训练或模型并行,限制了扩展性。
项目仅支持单GPU训练,无法扩展到多卡场景;训练数据仅使用Pile数据集的小部分,未公开具体采样量;对于>1B参数模型,硬件门槛依然很高;代码教学性强但生产可用性弱,缺乏优化如混合精度训练、梯度检查点等。
