今天,一本量化交易领域的“教科书级”开源项目——stefan-jansen/machine-learning-for-trading 单日暴涨717颗星,近30天累计增长2760星,创下区间峰值。这个包含150多个Jupyter Notebook的代码仓库,并非简单的“书籍配套代码”,而是一套从数据清洗到深度强化学习的完整交易策略工程化框架。在量化交易社区对“可复现研究”和“端到端工作流”需求激增的背景下,它正成为交易员和ML工程师的标配参考。
这个项目在做什么
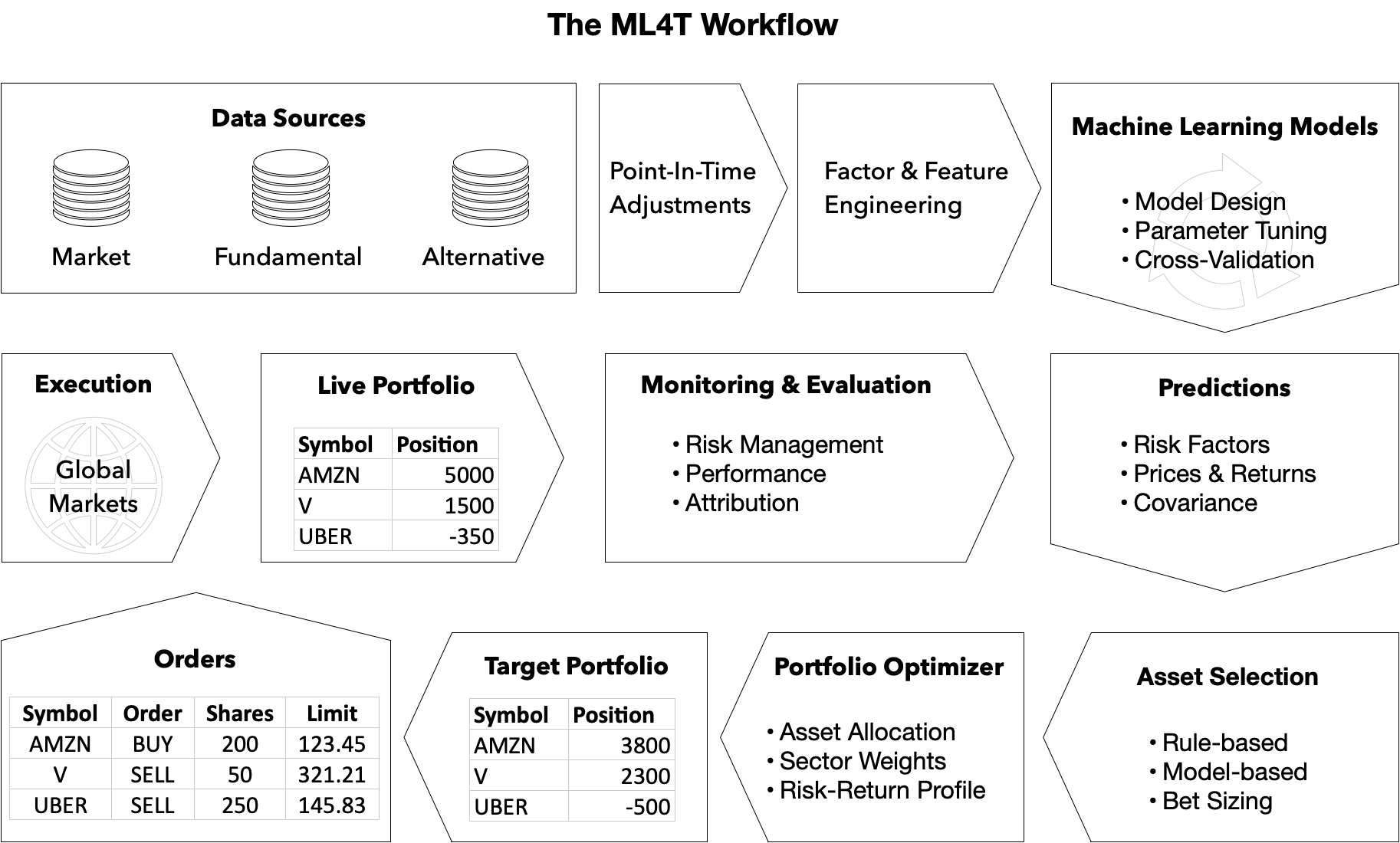
量化交易领域长期存在一个断层:学术论文里的ML模型往往停留在回测曲线,而实际交易需要处理数据漂移、特征工程、回测偏差等工程问题。stefan-jansen/machine-learning-for-trading 第二版正是填补这一空白的产物。它并非简单的“算法教程”,而是将ML for Trading定义为一条从数据源、特征工程、模型训练到策略回测的完整工作流(ML4T workflow)。
项目包含23个章节和150+个可执行Notebook,覆盖了从线性回归到深度强化学习的全谱系技术。特别值得注意的是,它新增了策略回测章节和100多个Alpha因子附录——这些不是理论推导,而是可直接运行的代码,比如用CNN处理市场数据、用GAN生成合成数据、用强化学习训练交易智能体。
为何此刻被关注
本期爆发并非偶然。2026年6月3日,项目在Hacker News和Reddit的r/algotrading板块被广泛推荐,核心原因是:随着量化交易从机构走向个人,市场对“可复现、可调试、可扩展”的开源参考实现需求井喷。相比QuantConnect等平台的黑盒策略,这个项目提供了完全透明的代码和详细的数学推导。
此外,第二版于2025年底发布,经过半年社区发酵,其价值被逐步认可。今天717颗星的峰值,恰好对应一篇深度评测文章在Twitter上的传播,该文章对比了它与PyAlgoTrade、Backtrader等框架的差异,指出其“学术严谨性”和“工业实用性”的平衡点。
技术上有何不同
与同类项目(如Quantopian的教程、PyPortfolioOpt)相比,这个项目有两个关键设计选择:
Notebook即文档:所有代码均以Jupyter Notebook形式呈现,且保持“已执行状态”。这意味着读者可以直接看到输出结果,无需本地运行。这种做法在GitHub上并不常见(通常Notebook只作为演示),但这里150多个Notebook每个都经过精心编排,甚至包含因书籍篇幅限制而省略的额外分析。
端到端工作流而非孤立的算法:大多数开源交易项目只提供某个模型的实现(如LSTM预测股价),但这里从数据获取(Yahoo Finance、SEC文件)到特征工程(技术指标、文本情感)、模型调参(Optuna集成)、策略回测(自定义引擎)全链路覆盖。例如,第14章展示了如何用BERT从财报电话会议中提取信号,并直接接入回测系统。
与另一个知名项目“ai-trading”(Stars约5000)相比,后者更偏向深度学习模型实验,而本项目强调“可解释性”和“金融背景”——每个算法都配有数学推导和金融直觉解释,这对实际交易至关重要。
谁应该用它
- 量化研究员/交易员:需要从零搭建策略回测框架,或复现学术论文中的信号。项目中的Alpha因子附录(100+因子)可直接作为特征池起点。
- ML工程师转型金融:想理解金融数据特殊性(非平稳性、信噪比低)如何影响模型选择。例如,第7章专门讨论时间序列交叉验证,这是标准ML课程缺失的。
- 金融专业学生:作为“动手学量化”的教材,配合书籍使用效果最佳。Notebook中的注释和额外分析比书籍更详细。
局限与开放问题
尽管项目质量极高,但仍有几个注意事项:
- 依赖书籍:代码注释虽多,但核心概念推导依赖书籍正文。单独看Notebook可能难以理解某些设计决策。
- 回测引擎非生产级:项目中的回测引擎是教学用途,不支持实盘交易所需的低延迟、订单簿模拟等功能。
- 数据源限制:示例数据主要来自免费源(Yahoo Finance、SEC EDGAR),对于高频交易或非美国市场需自行替换。
- 维护节奏:作者Stefan Jansen是独立作者,更新频率不如社区驱动项目。当前版本(2025年底)后尚未有重大更新。
"这不是一本代码附赠书,而是一套可复现的量化交易工程框架。"
"它填补了学术论文与实盘交易之间的工程断层。"
"150多个Notebook,每一个都是可执行的交易策略实验室。"
核心亮点
数据来源:TrendForge 历史采集
项目截图

2026年6月3日,项目在Hacker News和Reddit的r/algotrading板块被深度评测文章引爆。该文章对比了它与PyAlgoTrade、Backtrader等框架,指出其‘学术严谨性’和‘工业实用性’的独特平衡。量化交易从机构走向个人,市场对透明、可复现的开源参考实现需求激增,而本项目恰好提供了从数据到回测的完整链路,且代码质量极高。此外,第二版于2025年底发布,经过半年社区沉淀,价值被逐步认可,今日达到传播临界点。
量化研究员和交易员:需要可复现的策略框架和Alpha因子库;ML工程师转型金融:理解金融数据特殊性(非平稳性、低信噪比)对模型的影响;金融专业学生:作为‘动手学量化’的教材,配合书籍使用效果最佳。不适合需要实盘交易系统或高频策略的用户。
项目最突出的设计是‘Notebook即文档’——所有代码以已执行状态呈现,读者可直接查看输出,降低了复现门槛。与Quantopian教程(侧重平台API)和PyPortfolioOpt(仅组合优化)不同,本项目覆盖了从数据获取(Yahoo Finance、SEC文件)到特征工程(技术指标、文本情感)、模型调参(Optuna)、策略回测的全链路。特别值得关注的是其时间序列交叉验证实现(第7章)和GAN合成数据生成(第20章),这些在同类开源项目中罕见。
项目依赖书籍理解,单独看Notebook可能缺失背景。回测引擎为教学用途,不支持实盘交易。数据源限于免费源,高频或非美国市场需自行适配。作者独立维护,更新频率有限。
