今天,GitHub 上一个名为 opendataloader-pdf 的 Java 项目单日暴涨 9,191 颗星,16 天内从默默无闻跃升至 23,240 星。它声称自己是“AI 就绪数据的 PDF 解析器”,但真正引爆社区的,是其同时解决了两个截然不同的痛点:RAG 文档预处理的高精度结构化提取,以及 PDF 无障碍合规的自动化标记。在传统解析器(如 PyMuPDF、pdfplumber)与商业 OCR 服务之间,OpenDataLoader 用“确定性本地模式 + AI 混合模式”的架构,试图成为那个“全都要”的答案。
这个项目在做什么
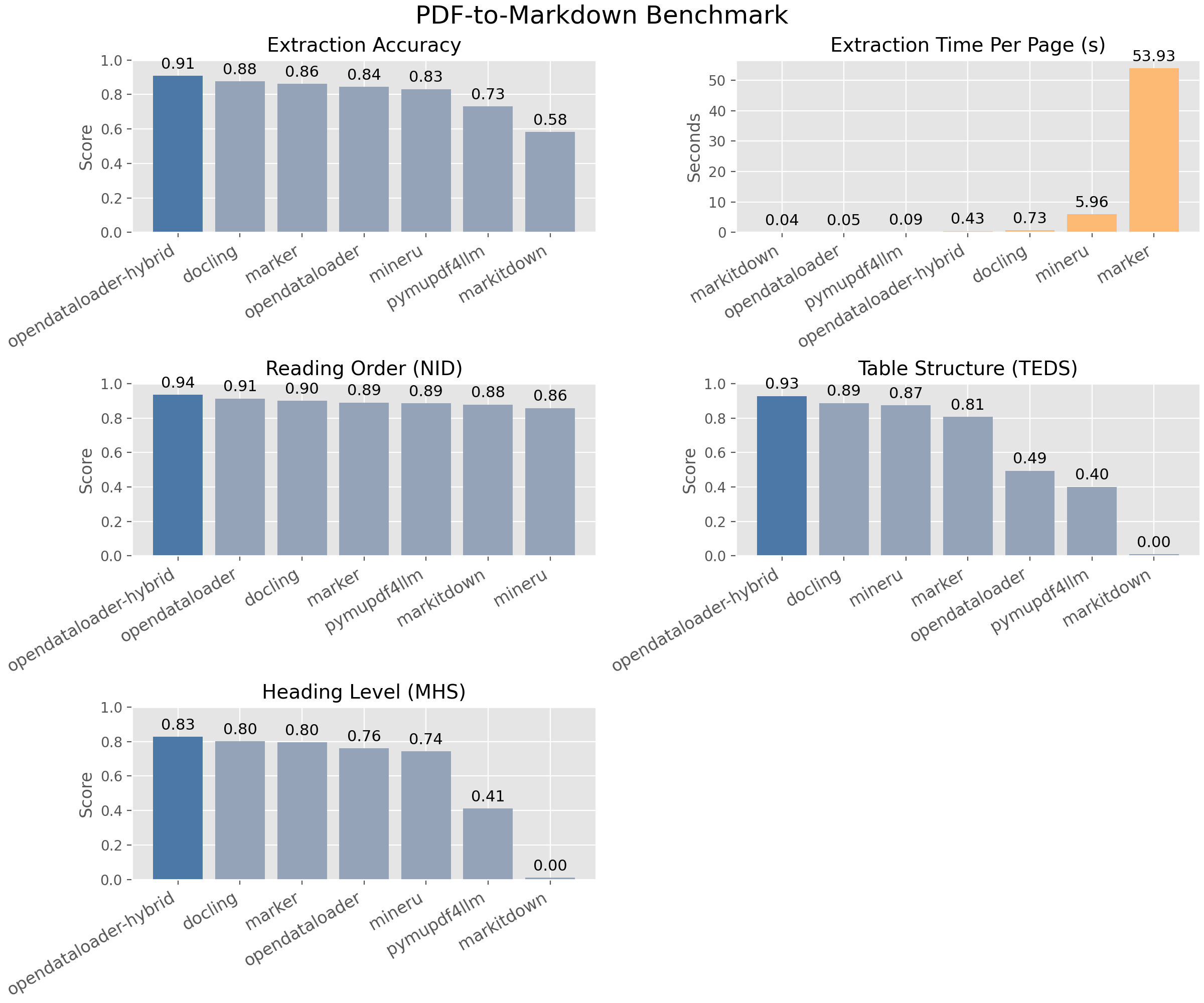
OpenDataLoader PDF 的核心是一个 PDF 解析引擎,输出格式包括带边界框坐标的 JSON、结构化 Markdown 以及 HTML。其独特之处在于双模式设计:确定性本地模式使用 XY-Cut++ 算法重建阅读顺序,无需任何外部依赖即可处理大多数 PDF;AI 混合模式则将复杂页面(如多栏布局、无边框表格、扫描文档)路由到后端 AI 模型,在基准测试中取得 0.907 的综合准确率,表格提取准确率达 0.928。
但真正让项目出圈的,是它在 PDF 无障碍自动化上的野心。项目宣称是“首个端到端开源工具”,能将未标记 PDF 自动转换为带标签的 Tagged PDF,为生成符合 PDF/UA 标准的合规文档奠定基础。这一功能在 2026 年 Q2 开源,直接回应了全球范围内日益严格的数字无障碍法规(如欧洲 EAA、美国 ADA 和 Section 508)。
为何此刻被关注
2026 年 3 月 31 日,项目单日获得 9,191 颗星,成为 GitHub 日榜冠军。这一爆发并非偶然:前一天,项目在 Hacker News 上被一篇题为“PDF accessibility is broken, and this open-source tool might fix it”的文章推荐,同时 Reddit 的 r/MachineLearning 和 r/programming 社区也出现了关于其 RAG 性能的讨论。
更深层的背景是,RAG 应用开发者长期被 PDF 解析的“最后一公里”困扰:传统工具要么丢失表格结构,要么无法精确定位原文位置。而企业合规团队则面临手动修复 PDF 的高昂成本(每份 50-200 美元)。OpenDataLoader 用一个项目同时触及这两个群体,形成了跨领域的传播效应。
技术上有何不同
与 PyMuPDF 相比,OpenDataLoader 的本地模式在阅读顺序重建上更优——PyMuPDF 依赖 PDF 内部结构,对于扫描件或结构混乱的 PDF 几乎无能为力。与 pdfplumber 相比,OpenDataLoader 原生支持表格提取(包括无边框表格)和公式识别,而 pdfplumber 需要额外的手动规则。
在 OCR 方面,项目内置了 80+ 语言的 OCR 引擎,支持 300 DPI 以上的低质量扫描件。这使其在扫描文档数字化场景中,可以替代 Tesseract + 布局分析的自定义管线。
最值得关注的设计选择是“混合模式”的架构:项目不强制使用 AI,而是通过启发式规则判断页面复杂度,仅在必要时调用 AI 模型。这既保证了简单页面的处理速度(本地模式可在毫秒级完成),又为复杂页面保留了 AI 的精度。
谁应该用它
- RAG 应用开发者:需要将 PDF 转换为带坐标的结构化数据,用于分块和精确溯源。项目提供 Python、Node.js、Java SDK 和 LangChain 集成,3 行代码即可启动。
- 企业合规团队:需要批量生成符合 PDF/UA 标准的无障碍文档。自动标记功能免费开源,但完整的 PDF/UA-1/2 导出是商业附加组件。
- 学术研究机构:需要解析 arXiv 论文中的多栏布局、LaTeX 公式和复杂表格。混合模式可处理这些边缘情况,输出结构化 Markdown 用于索引或元分析。
- 档案馆与图书馆:需要数字化历史扫描文档。内置 OCR 和布局分析引擎可还原正确的阅读顺序,输出带坐标的 JSON。
局限与开放问题
尽管项目表现亮眼,仍有几个关键问题需要关注。首先,AI 混合模式依赖外部后端,这意味着用户要么需要自建 AI 服务,要么使用项目提供的云端 API(可能产生费用)。其次,PDF/UA 合规的最后一公里是商业功能——自动标记生成的是 Tagged PDF,但最终导出为 PDF/UA-1 或 PDF/UA-2 需要企业许可。对于预算有限的团队,这可能是一个阻碍。
此外,项目的 Java 依赖(需要 Java 11+)可能让纯 Python 开发者感到不便。虽然提供了多语言 SDK,但核心引擎仍运行在 JVM 上,增加了部署复杂度。最后,项目的长期维护能力尚未经过考验——毕竟它才诞生不到一个月。
"“PDF accessibility is broken, and this open-source tool might fix it” —— Hacker News 热帖标题"
"“我们不是另一个 PDF 解析器,我们是 PDF 解析的终结者” —— 项目 README"
"“手动修复一份 PDF 要 50-200 美元,而 OpenDataLoader 把它变成了零成本”"
核心亮点
数据来源:TrendForge 历史采集
项目截图

项目在 2026 年 3 月 31 日单日新增 9,191 星,主要驱动力来自 Hacker News 首页推荐和 Reddit 社区讨论。其跨领域定位——同时解决 RAG 开发者的“结构化提取”痛点和企业合规团队的“无障碍自动化”痛点——吸引了两个原本不重叠的受众群体。此外,项目在基准测试中排名第一的公开数据,以及“首个开源端到端 PDF 无障碍工具”的叙事,在社交媒体上形成了病毒式传播。
RAG 应用开发者:需要将 PDF 转换为带坐标的结构化数据,用于分块和精确溯源,支持 Python/Node/Java SDK 和 LangChain 集成。企业合规团队:需要批量生成符合 PDF/UA 标准的无障碍文档,自动标记功能免费开源。学术研究机构:需要解析复杂学术 PDF(多栏、公式、无边框表格),混合模式可处理边缘情况。
项目的核心创新在于“确定性+AI”混合架构:本地模式使用 XY-Cut++ 算法(一种改进的递归 XY 切割)重建阅读顺序,无需外部依赖;混合模式则通过启发式规则判断页面复杂度,仅对复杂页面调用 AI 模型。这种设计在速度和精度之间取得了平衡,避免了纯 AI 方案的高延迟和纯规则方案的脆弱性。与 PyMuPDF 相比,其阅读顺序重建更准确;与 pdfplumber 相比,原生支持无边框表格和公式识别。但 AI 模式依赖外部后端,可能增加部署复杂度。
AI 混合模式依赖外部后端,自建或使用云端 API 可能产生费用。PDF/UA 完整导出为商业功能,开源版仅生成 Tagged PDF。核心引擎需 Java 11+,增加 Python 开发者部署复杂度。项目诞生不足一月,长期维护能力待验证。
使用场景
使用该解析器将PDF转换为带边界框坐标的JSON或结构化Markdown,保留表格、公式等语义信息,便于后续分块和精确溯源。
启用项目的混合模式(内置80+语言OCR),结合布局分析引擎,能准确识别扫描文档的文字、表格,并还原正确的阅读顺序。
使用项目的自动标记功能(2026年Q2开源),将未标记PDF转换为带标签PDF(Tagged PDF),为生成合规PDF/UA文档奠定基础。
利用混合模式(AI辅助)处理复杂页面,能准确提取多栏文本、无边框表格、LaTeX公式,并为图表生成AI描述。
